论文: Spatio-Temporal Modeling and Prediction of Visual Attention in Graphical User Interfaces
作者: Xu, Pingmei, Yusuke Sugano, and Andreas Bulling.
发表会议: CHI 2016
这篇文章中,Pingmei Xu等人提出了一个 对于GUI中人的视觉注意进行时空预测的模型。这个模型基于图形界面、用户的鼠标和键盘输入,不依赖于眼动追踪仪器,能够帮助我们很好地捕捉和预测用户在GUI上的注意力。
在人机交互的领域,视线(Gaze)有着重要的意义。它既可以作为外显的输入,用于对沉浸式设备(例如虚拟现实眼镜)进行交互控制,同时也是一种内隐的输入,表现用户的兴趣与关注。在人机交互中,视线的使用也有着一些基本的局限性。对于视线的估计需要特殊的眼动跟踪仪器,这些仪器往往造价不菲,难以入手,因此并非在大多数场合都是通用的。此外,眼动追踪仪只能告诉我们用户视线当前和过去位置,无法预测用户未来可能关注的位置。对于这些问题,一种常见解决办法是使用视觉注意的计算模型。典型地,它会将一张图片作为输入,预测那些局部特征和周围显著不同的区域,认为它们最可能在接下来被用户注意到。这些模型有着局限性,主要在于:没有考虑到用户的其他输入;没有考虑到界面信息;没有考虑到用户的交互历史。
在这篇文章中,作者提出了一个用于预测用户时空视觉注意的计算模型,基于WIMP(window,icons, menus, pointer)式的GUI,将用户的鼠标键盘输入连同界面信息一同考虑进去。作者同时还介绍了一种对于UI布局进行整合的方法,以及对于提出的模型进行了比较与分析。

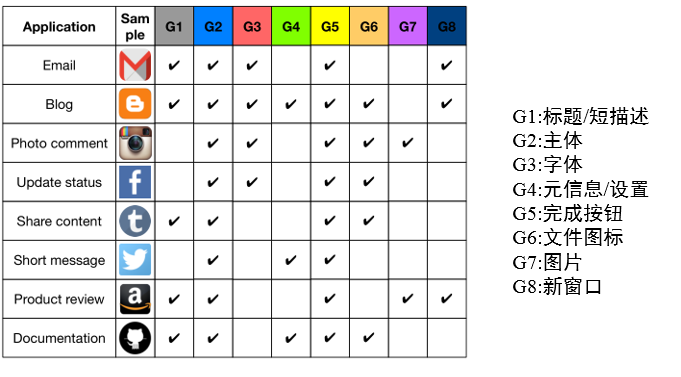
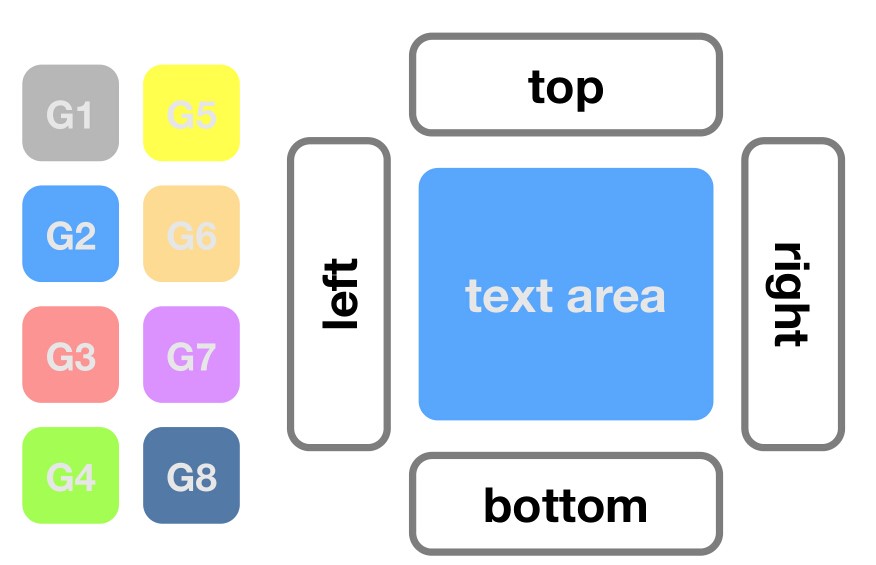
由于现实中的UI布局五花八门,种类繁多,为了能够使这个模型有更广泛的适用性,同时也为了更好地进行分析,作者选择文本编辑界面作为基础,对于这些UI布局进行了整合,得到一个通用的UI模型。作者首先对于现实中的UI(例如gmail、blog等)进行了采样,对于每种应用确认了关键的UI组件,并在不同应用中将它们匹配对应起来,得出了8个不同的功能组件。对于每一种特定的应用,在有了其功能列表之后,根据几个特定的规则,我们就可以产生通用的布局。作者在本文中定义的规则包括:主体和描述放在正中间;常规的功能组件放在主体上下左右四个部分,每个部分不超过三个功能组;弹出的新窗口出线在正中间。
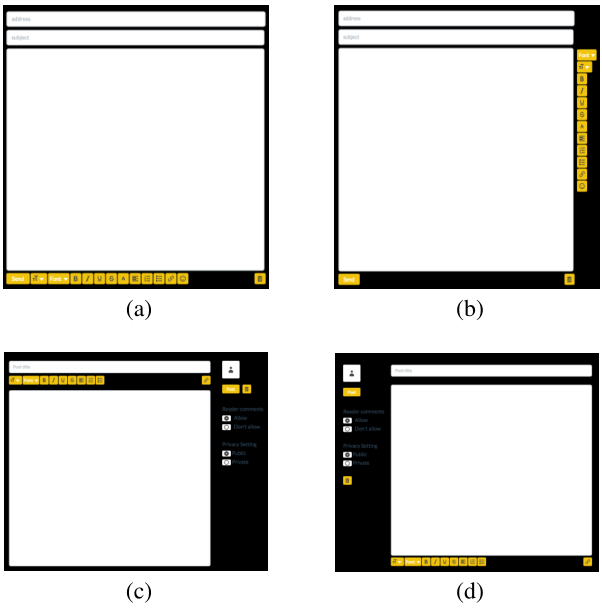
根据通用UI模型结合现实的应用实例,作者得到了30个功能等价的不同UI布局,然后设计一个用户研究来采集行为数据。试验招募了18名被试(6女12男,20-30周岁),进行了1小时实验,被试会获得10欧元报酬。试验仪器包括一台电脑,显示器分辨率1920*1200,人的脑袋固定在距离显示器55cm的位置;Tobii TX300固定眼动追踪仪。软件环境为Chrome浏览器全屏模式(背景黑色)下Javascript实现的软件。试验记录了鼠标的时序位置,以及鼠标点击,键盘输入以及UI的动态变化。实验程序包括三个部分,每个部分6-7个文本编辑任务,每一个部分结束后有2分钟休息。对于每个任务,UI布局是从之前提到的30个布局中选取的。在每个任务前被试会被告知一个大致的主题:“关于家乡的博文”、邀请朋友吃晚餐的email。这些GUI具有完整的功能,被试被鼓励尽可能多地使用这些功能,同时尽快完成任务(写不超过5个句子)。在实验结束后被试对于这些任务的真实性进行1-5的打分(平均分4.3)。
为了理解视觉注意,用户关注点的时间变化是一个非常重要的因素。不同的用户有不同的行为方式,然而如果在一个更高的层次确实存在着一种典型的工作流程的话,那么它就可以作为一个有用的线索,用于预测用户感兴趣的组件以及对应的关注点。从收集到数据中,作者发现了三种频繁出现的模式:鼠标跟随视线;在文本编辑过程中,视线聚焦于光标;当视线检查文本内容和UI组件时,鼠标保持静止。


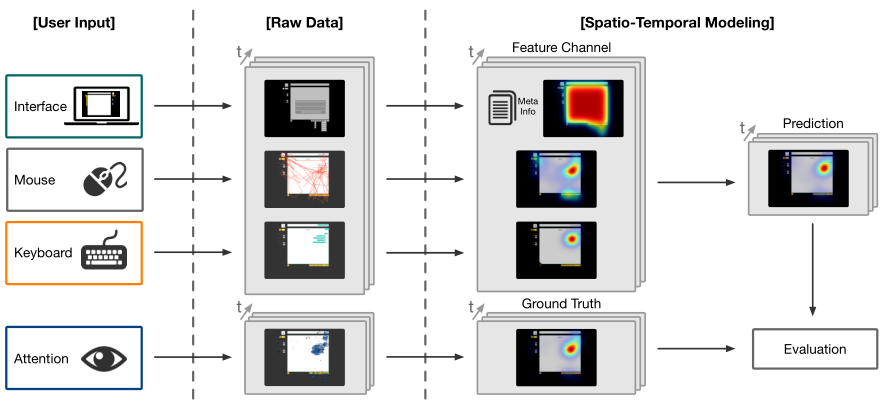
在对于用户的时空视觉注意进行建模时,作者将对于注意的映射当作是一个回归问题,这个问题就是要为以下的公式找到一个最优化得解。
作者将全部case下的用户完成任务所用的时间进行归一化,得到了归一化的后每个时间点的数据。其中U是用户,T是任务,P是像素,m是像素的属性向量,由界面、鼠标和键盘三个部分的输入信息得到,v是像素的值,由眼动追踪仪测得。mk和v都是0-1化的数值,1代表鼠标、光标、组件或视线落在该像素上,0代表不落在。的w是待训练的参数,λ是用来避免过拟合的规范化参数。在静态模型中,模型将所用时间点的数据用于训练,得到静态时空时空注意映射,反映的是用户对于界面整体的注意分布概率。在动态注意预测的离线模型下,每个时间点t前后d时间段的数据用于训练,得到该时间点t的注意分布概率。动态注意预测的在线模型是以离线模型的基础,但由于未知用户完成任务时间,无法得到对应的归一化时间。为此,该模型训练一个m(t)的函数,用于任务进行的实际时间所对应的归一化时间。
作者对于该模型进行了定量的评估,结果显示预测结果和眼动追踪仪器收集到的数据高度一致,这个模型能够很好地对于用户视线进行预测。

✉️ zjuvis@cad.zju.edu.cn